

A NVIDIA divulgou hoje (13), um blogpost sobre como a Inteligência Artificial generativa transformou como as pessoas criam, imaginam e interagem com conteúdo digital.
À medida que os modelos de IA continuam a evoluir em capacidade e complexidade, eles exigem cada vez mais VRAM (a memória da placa de vídeo). O modelo base Stable Diffusion 3.5 Large (Grande), por exemplo, utiliza mais de 18 GB de VRAM, limitando a quantidade de sistemas capazes de executá-lo com eficiência.
Ao aplicar a quantização ao modelo, é possível remover camadas não críticas ou executá-las com menor precisão. As GPUs NVIDIA GeForce RTX Série 40 e a geração Ada Lovelace de GPUs NVIDIA RTX PRO oferecem suporte à quantização FP8 para facilitar a execução desses modelos quantizados, enquanto as GPUs NVIDIA Blackwell de última geração também adicionam suporte ao FP4.
A NVIDIA colaborou com a Stability AI para quantizar seu modelo mais recente, o Stable Diffusion (SD) 3.5 Grande, para FP8, reduzindo o consumo de VRAM em 40%. E otimizações adicionais nos modelos SD3.5 Grande e Médio, utilizando o kit de desenvolvimento de software (SDK) NVIDIA TensorRT, dobraram o seu desempenho.
Além disso, o TensorRT foi redesenhado para os PCs com GPUs GeForce RTX, combinando seu desempenho com a construção de engines just-in-time (JIT) no próprio dispositivo em um tempo 8 vezes menor, permitindo uma implantação de IA fluida em mais de 100 milhões de PCs RTX IA. O TensorRT para RTX já está disponível como um SDK independente para desenvolvedores.

IA Acelerada por RTX
A NVIDIA e a Stability AI estão ampliando o desempenho e reduzindo os requisitos de VRAM do Stable Diffusion 3.5, um dos modelos de geração de imagens por IA mais populares do mundo. Com a aceleração e a quantização proporcionadas pelo NVIDIA TensorRT, os usuários agora podem gerar e editar imagens de forma mais rápida e eficiente em GPUs NVIDIA RTX.
Para contornar as limitações de VRAM do SD3.5 Grande, o modelo foi quantizado com o TensorRT para FP8, reduzindo o consumo de VRAM em 40%, para 11 GB. Isso permite que cinco modelos de GPUs GeForce RTX Série 50 executem o modelo diretamente na memória, ao invés de somente um.
Os modelos SD3.5 Grande e Médio também foram otimizados com o TensorRT, da NVIDIA, uma infraestrutura de IA desenvolvida para aproveitar ao máximo os Tensor Cores. Ele otimiza os pesos e os gráficos do modelo, as instruções que definem como o modelo deve ser executado, especificamente para GPUs GeForce RTX.
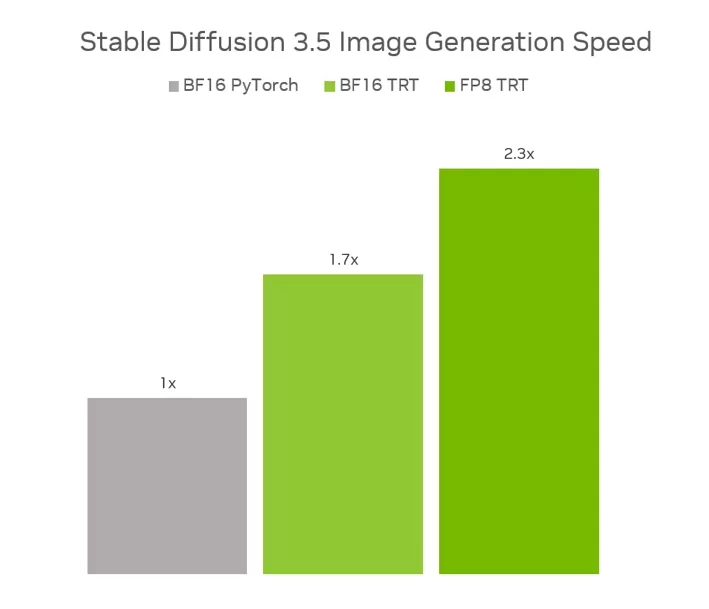
Combinados, o TensorRT com FP8 oferecem um aumento de desempenho de 2.3x no SD3.5 Grande em comparação com a execução do modelo original em BF16 no PyTorch, utilizando 40% menos memória. Já no SD3.5 Médio, o TensorRT com BF16 proporciona um ganho de desempenho de 1.7x em relação ao BF16 PyTorch.
Os modelos otimizados já estão disponíveis na página da Stability AI no Hugging Face.
A NVIDIA e a Stability AI também se juntaram para lançar o SD3.5 como um microsserviço NVIDIA NIM, facilitando o acesso e a implementação do modelo por criadores de conteúdo e desenvolvedores em uma ampla variedade de aplicações. A previsão de lançamento do microsserviço NIM está programada para julho de 2025.
TensorRT para RTX SDK Já Disponível
Anunciado durante o Microsoft Build, e já disponível como parte do novo framework Windows ML em versão prévia, o TensorRT para RTX agora está disponível como um SDK independente para os desenvolvedores.
Anteriormente, os desenvolvedores precisavam gerar e combinar previamente engines TensorRT para cada tipo de GPU, um processo que gerava otimizações específicas para cada GPU, mas exigia um tempo considerável de produção.
Com a nova versão do TensorRT, os desenvolvedores podem criar uma engine TensorRT genérica que é otimizada no próprio dispositivo em questão de segundos. Essa abordagem de compilação just-in-time (JIT) pode ser realizada em segundo plano durante a instalação ou na primeira utilização do recurso.
O SDK de fácil integração, agora está 8 vezes menor e pode ser acionado através do Windows ML, a nova infraestrutura de inferência de IA da Microsoft no Windows. Os desenvolvedores podem baixar o novo SDK na página NVIDIA Developer ou testá-lo na prévia do Windows ML.
Para mais detalhes, confira o blogpost técnico da NVIDIA.









